



「私たちは長年にわたり、信頼できる格付けの提供に注力し、現地データチームへの投資を重ねてきました。これにより当社の格付けの正確性は確保されていますが、購入者が検討している数千のプロジェクトにわたるスケールを実現することはできません。」

カーボンクレジット調達の最新動向について詳しくは、当社の記事「Key Takeaways for 2025」をご覧ください。調達戦略を改善するための、データに基づく5つのヒントをご紹介しています。

加えて:Connect to Supplyをご利用のお客様は、Sylveraのその他のツールもご利用いただけます。プロジェクトの格付け確認や強みの評価、高品質なカーボンクレジットの調達に加え、プロジェクトの進捗状況のモニタリング(特に発行前段階で投資している場合)も可能です。
Sylveraの無料デモを予約して、調達機能やレポーティング機能を体験しましょう。
炭素プロジェクトを分析する際、Sylvera 機械学習(ML)と複数種類の衛星データを活用し、森林と土地被覆の特定の特徴を特定します。これらの特徴の例には以下が含まれます:
- 森林と非森林
- キャノピーハイト
- キャノピーカバー
- 地上バイオマス
この記事では、当社がさまざまなプロジェクト分析にMLをどのように活用し、他社との差別化を図っているかについて概説します。
機械学習のファクトシートはこちらからダウンロードできます。
機械学習とは?
MLを活用することで、プロジェクト地域(PA)内で何が起きているのかをスケールごとに把握することができます。プロジェクト内の小さなエリアを手作業でサンプリングする(時間がかかり、精度が低い)よりも、世界中のどこにでもあるプロジェクトエリア全体を評価することができます。MLモデルから最も正確なアウトプットを得るために、私たちは特定の生物群や地域で独自のモデルをトレーニングしています。
すべてのPAについて、シェープファイル(プロジェクトエリアのアウトライン)を作成します。このシェープファイルを使って、衛星画像からプロジェクトの境界線に該当するピクセルを抽出します(通常は10m~30mの解像度)。Sylvera 、PA内のすべてのピクセルを単独で、また隣接するピクセルのコンテキスト(これはディープラーニングの強力な機能です)の両方で調べます。
例えば、森林の成長を評価しようとする場合、MLモデルを使ってPA内のすべてのピクセルのキャノピー高を推定します。そのために、ラベル付けされた何万ものデータポイントを与えて、林冠高を識別するモデルをトレーニングします。これにより、モデルは樹冠の高さに関連する特定の特徴を識別するように「学習」します。
その後、炭素プロジェクトの各エリアでモデルを実行し、この例では樹冠高を推定します。同じ地域で複数年にわたりモデルを実行することで、森林面積の経年変化を見ることができます。
複数のデータソースの組み合わせ
モデルの訓練と実行には、複数の種類のデータを利用します。それぞれのタイプで異なるデータを提供することで、特定の特徴を検出することができます。
ARRプロジェクトの分析にMLを使用する方法
ARR(Afforestation, Reforestation, Revegetation)プロジェクトは、「除去」のカテゴリーに分類される自然ベースの解決策です。 一般的には、植林によって荒廃した不毛の土地を転換することを目的としています。
ARRプロジェクトのパフォーマンスを評価するためには、森林の消失と同様に、新たに森林が成長した地域を特定することが不可欠です。私たちはキャノピーの高さをこれらの地域を特定するための代用品として使用しています。
次ページの画像は、当社独自の機械学習モデルと衛星データを活用して、ARRプロジェクト地域内の樹冠高を経時的に推定し、森林が成長している地域を特定する方法を示しています。
この例では、プロジェクトのさまざまなエリアで樹冠の高さが増加しているのがわかります。これは、異なる時点で新しい森林が植林され、成長していることを示しています。
これらの結果をプロジェクトの報告書と比較し、両者が一致しているか、あるいは食い違いがないかを確認します。
- 報告されたのと同じ面積の森林が成長し、未報告の損失がなければ、炭素スコアは100%になります。
- 森林の成長面積が報告された面積より少なかったり、 森林の損失が報告されていなかったりした場合、 カーボンスコアは100%を下回ります。
キャノピーの高さ(黄色と緑色)は、時間の経過とともにプロジェクト内のさまざまな地域で増加しています。これは、新しい森林の植栽と成長のエリアを示しています。
このことは、Sylvera 格付けにどのように反映されるのですか?
私たちのモデリング手法の結果は、プロジェクト地域内の現場で実際に起こっていることを代表するものであることを確認し、カーボン・スコアの高い精度を保証するために、品質管理プロセスにかけられます。
また、このMLの結果を、格付けフレームワークの「追加性」コンポーネントで使用し、プロジェクトエリアの不適格性をテストします。
- カーボンオフセットプロジェクトを開発する際、プロジェクトデベロッパー プロジェクト開始前に存在していた原生林をプロジェクトデベロッパー 、その伐採された森林面積は対象外とみなされ、過剰クレジット発行のリスクとなります。このリスクを把握するために、当社は機械学習(ML)の結果を活用し、森林伐採が行われた時期に加え、過去に存在した原生林の有無を追跡しています。
REDD+プロジェクトの分析にMLを使用する方法
REDD+(Reduce Emissions from Deforestation and Forest Degradation:森林減少・劣化からの排出削減)プロジェクトは、「回避」の範疇に入る一般的な自然ベースのソリューションです。森林に蓄積された炭素に金銭的価値を与え、温室効果ガス排出につながる人為的影響を削減するインセンティブを加えることで、既存の森林を保全することを目的としています。
REDD+プロジェクトの成果を評価するためには、一定期間における森林の消失と維持の違いを明らかにする必要があります。
次ページの画像は、私たちが独自の機械学習モデルと衛星データを活用し、REDD+プロジェクト地域内で森林から非森林へと変化した地域を経時的に検出することで、森林喪失地域を特定している様子を示しています。
私たちのモデリング手法の結果は、プロジェクト地域内の現場で実際に起こっていることを代表するものであることを確認し、炭素スコアの精度を高くするために、品質管理プロセスを経ています。
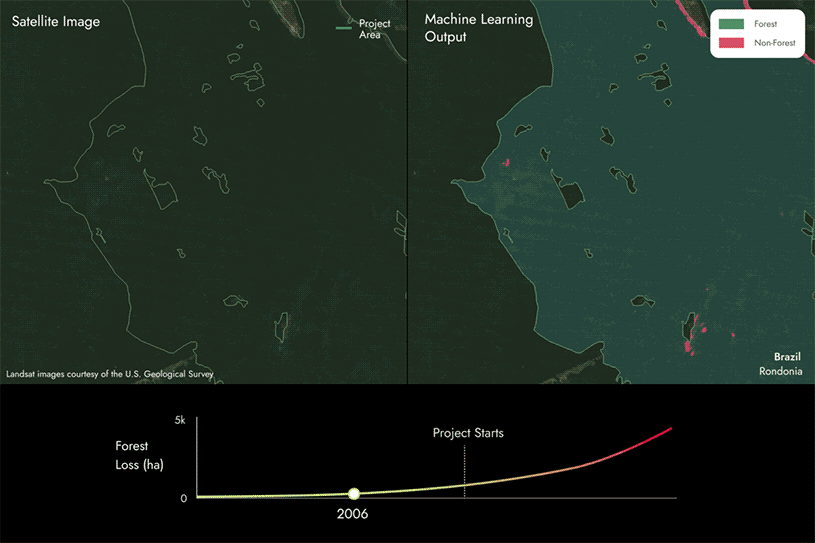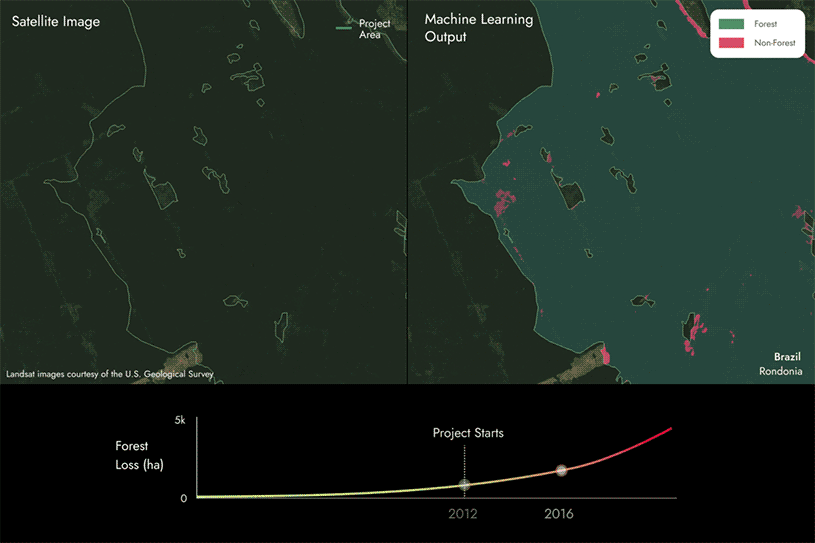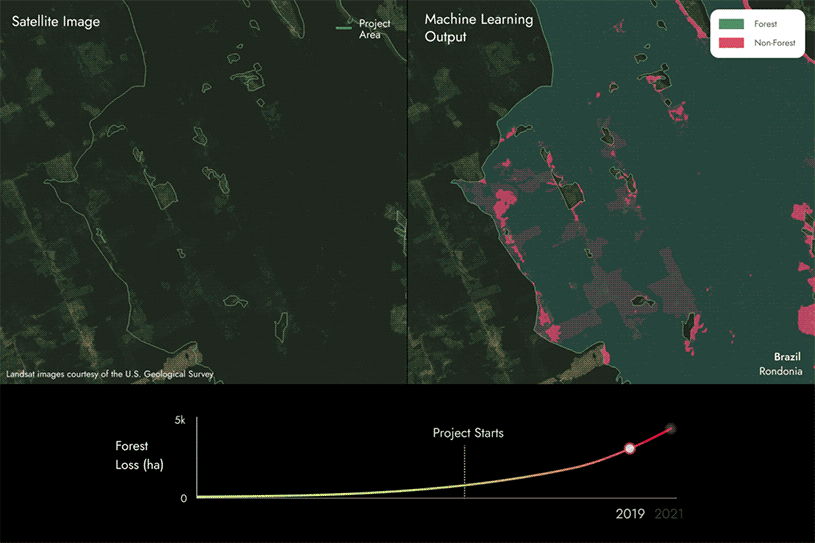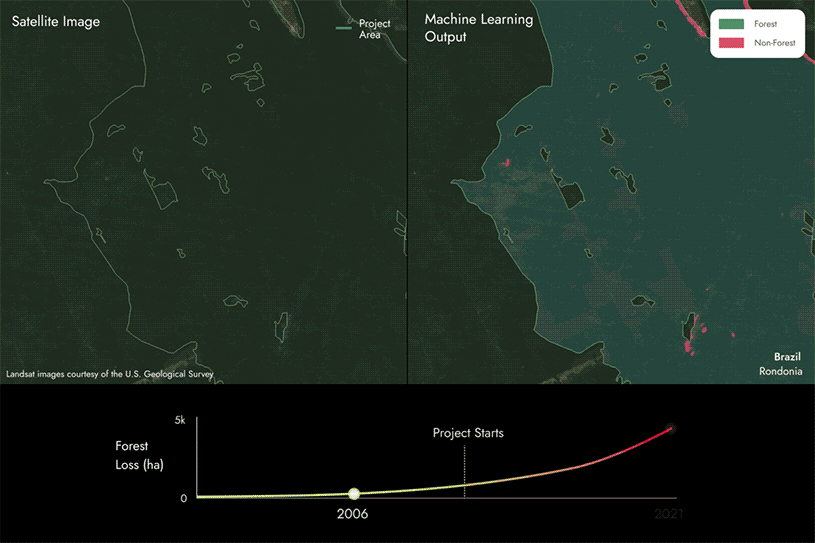
この場合、森林から非森林へと変化しているエリアがいくつかあることがわかりますが、これは時間の経過とともにプロジェクトエリア内で森林が減少していることを示しています。
そして、これらの結果をプロジェクトの報告書と比較し、両者が一致しているか、あるいは食い違いがないかを確認します。
- 報告された森林損失よりも多いことが判明した場合、炭素スコアは100%を下回ります。報告されていない森林損失が多ければ多いほど、スコアは低くなります。
IFMプロジェクトの分析にMLを使用する方法
改善された森林管理(IFM)は、農林業・土地利用プロジェクトのカテゴリーです。これらの森林管理活動により、森林内の炭素蓄積量の増加、および/または林業活動から排出される温室効果ガスの削減が図られます。
IFMプロジェクトのパフォーマンスを評価するために、炭素蓄積量の変化をもたらす活動を特定します。これらの活動の代理として樹冠被覆を使用し、ディープラーニングと回帰モデルを組み合わせて、これらの活動が行われた地域の規模を特定します。
下の画像は、プロジェクト内のさまざまな地域における森林被覆の相対的な変化を示す地図です。このような森林被覆の変化は、炭素ストックに相対的な影響を与えます。
SylveraMLは競合他社とどう違うのですか?
Sylvera機械学習の専門知識と能力により、他の企業では不可能な炭素プロジェクトに関する情報を正確に得ることができます。また、常に業界の最先端で活動できるよう、将来の研究ストリームにも投資しています。
Sylvera 、各データポイント(ピクセル)を個別に評価する従来の機械学習に加え、画像のコンテキストをより深く理解できるディープラーニングアルゴリズムも適用しています。これにより、推定と分析の精度が向上し、異なる地域や期間にまたがる一般化された予測が可能になります。
Sylvera 光学データだけに頼らず、光学、SAR/レーダー、LiDARといったあらゆるEOデータを活用しています。近々、ハイパースペクトルデータを私たちの手法に取り入れる予定です。
グラウンド・トゥルーシング・キャンペーン
Sylvera 、樹木と地上バイオマスに蓄積された炭素に関する世界最大のデータセットを構築するため、森林をLiDARスキャンしています。
このLiDAR参照データの量と質は他に類を見ません。世界中の様々なバイオームでこの膨大な量のデータを収集することで、Sylvera 衛星データを使用して、森林のバイオマスおよび炭素蓄積量の両方をかつてない精度で推定することができます。
.avif)
Sylvera 、LiDARを使用した3次元森林データを参照データとして使用できるほど十分に収集した、世界で唯一の評価プラットフォームです。現在、私たちはこのデータを使ってEOベースの機械学習モデルを訓練し、キャリブレーションを行い、その精度を高めています。これは私たちの重要な研究開発の流れのひとつであり、将来的には私たちの格付けに使用される予定です。




