



“多年来,我们对实地数据团队投入了大量资源,致力于产出值得信赖的评级。虽然这确保了我们评级的准确性,但无法满足买家在数千个项目中进行评估所需的规模。”

如需了解碳信用额采购趋势的更多信息,请阅读我们的《2025年关键要点》一文。文中分享了五条基于数据的建议,助您优化采购策略。

还有一点:Connect to Supply 的客户还可以使用Sylvera 的其他工具。这意味着您可以轻松查看项目评级并评估单个项目的优势,采购优质的碳信用额,甚至监控项目动态(特别是如果您在发行前阶段进行了投资)。
在分析碳项目时,Sylvera 机器学习(ML)和多种类型的卫星数据,以识别森林和土地覆盖的特定特征。这些特征的示例包括:
- 森林与非森林
- 冠层高度
- 顶篷罩
- 地上部生物量
本文概述了我们如何利用机器学习进行各类项目分析,以及这如何使我们脱颖而出,领先于竞争对手。
点击此处下载我们的机器学习简介。
什么是机器学习?我们为什么要使用它?
借助机器学习,我们可以大规模地观察项目区域(PA)内的动态。与在项目内手动抽样小范围区域(这种方法既耗时又不够精确)相比,我们能够评估位于世界各地的整个项目区域。为了从机器学习模型中获得最准确的输出结果,我们针对特定的生物群落和地理区域训练专有模型,并将其应用于不同类型的碳项目。
针对每个保护区(PA),我们会创建一个shapefile(即项目区域的轮廓图)。我们利用该shapefile从卫星影像中提取位于项目边界内的像素(通常分辨率为10米至30米)。Sylvera 单独Sylvera 保护区内的每个像素,并结合其邻近像素Sylvera 综合Sylvera (这是深度学习的一项强大功能)。
例如,如果我们要评估森林生长情况,就会利用机器学习模型来估算保护区(PA)内所有像素的林冠高度。为此,我们会通过向模型输入数万个标注数据点,来训练它识别林冠高度。这样,模型就能“学会”识别与林冠高度相关的特定特征。
随后,我们将模型应用于每个碳项目区域,以估算——在本例中——林冠高度。通过对同一区域进行多年模型运行,我们可以观察到森林面积随时间的变化。
整合多个数据源
我们利用多种类型的数据来训练和运行模型。每种类型的数据各不相同,这使我们能够识别出特定的特征。
我们如何利用机器学习进行ARR项目分析
造林、再造林和植被恢复(ARR)项目是属于“移除”类别的基于自然的解决方案。这些项目通常旨在通过植树造林来恢复退化和荒芜的土地。
为了评估ARR项目的成效,必须确定新造林区域以及森林损失区域。我们利用林冠高度作为指标来识别这些区域。
下页的图片展示了我们如何利用专有的机器学习模型和卫星数据,通过估算ARR项目区域内林冠高度随时间的变化,来识别森林生长区域。
在这个示例中,您可以看到项目不同区域的林冠高度有所增加。这表明了不同时间点新造林和森林生长的区域。
我们将这些结果与项目报告进行对比,以确定它们是否一致,或者是否存在差异。
- 如果我们确认的森林增长面积与报告一致,且没有未报告的损失,那么碳评分将为100%
- 如果我们发现实际森林增长面积小于报告数据,或者存在未报告的森林损失,那么碳评分将低于100%
随着时间的推移,项目不同区域的林冠高度(黄色和绿色)逐渐增加。这表明这些区域正在进行新造林并呈现生长态势
这将如何影响Sylvera 的Sylvera 评级?
我们建模方法得出的结果需经过质量控制流程,以确保其能真实反映项目区域内实际情况,并确保碳评分具有较高的准确性。
我们还将在评级框架的“增量性”部分运用机器学习结果,以检验项目区域是否不符合资格。
- 如果项目开发商在开发碳抵消项目时,砍伐了项目启动前已存在的原始森林,则被砍伐的森林面积将被视为不符合资格,并构成超额核算的风险。为了帮助我们理解这一风险,我们利用机器学习模型的结果来追踪历史上的原始森林分布情况,以及森林砍伐发生的确切时间点。
我们如何利用机器学习进行REDD+项目分析
REDD+( 减少毁林和森林退化所致排放量)项目是一种常见的基于自然的解决方案,属于“避免”类别。其目标是通过赋予森林中储存的碳以经济价值,并提供激励措施以减少可能导致温室气体排放的人类活动,从而保护现有森林。
为了评估REDD+项目的成效,有必要在一定时期内区分森林损失与森林保留的情况。
下一页的图片展示了我们如何利用专有的机器学习模型和卫星数据,通过检测REDD+项目区域内某片区域随时间推移是否从森林转变为非森林,从而识别森林损失区域。
我们建模方法得出的结果需经过质量控制流程,以确保其能真实反映项目区域内实际情况,并确保碳评分具有较高的准确性。
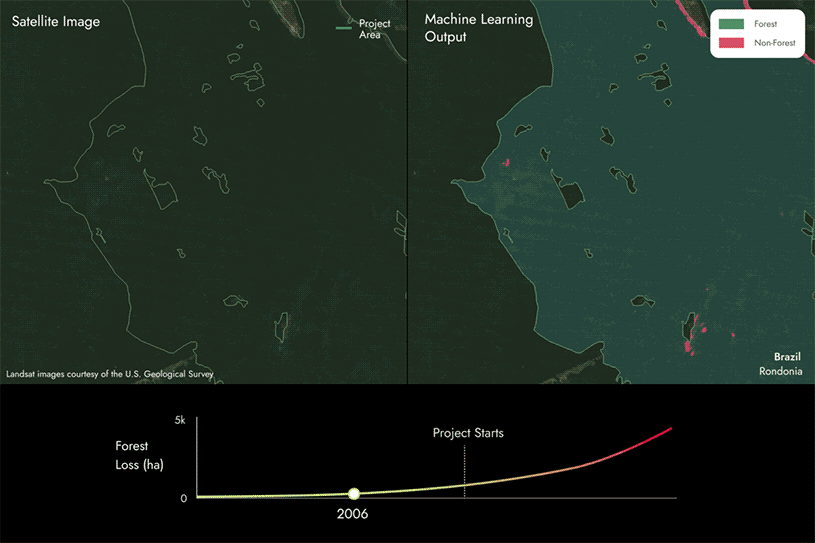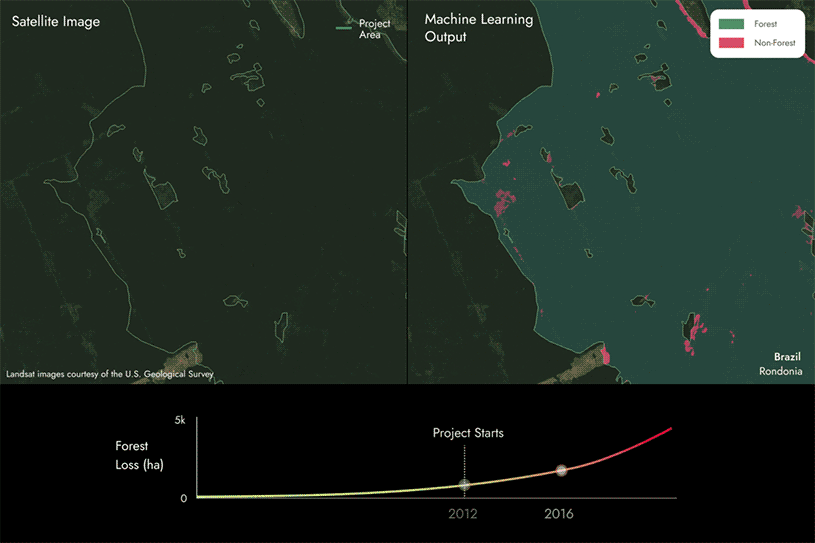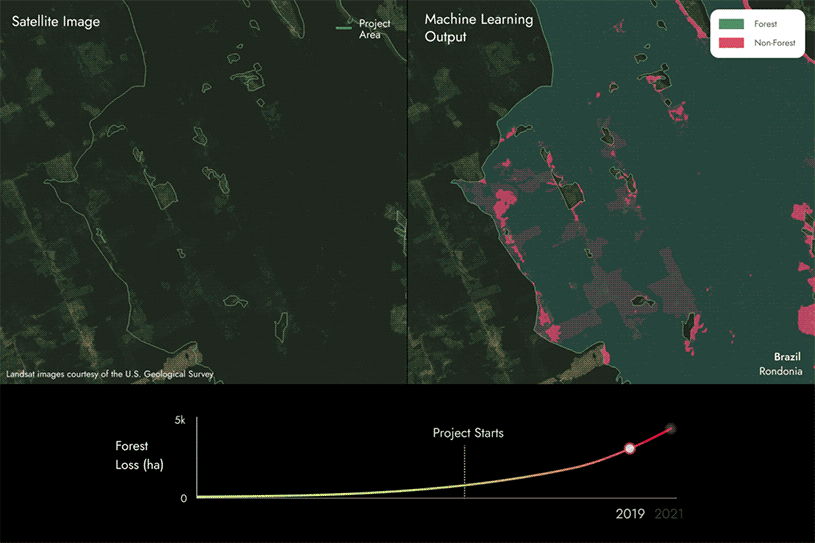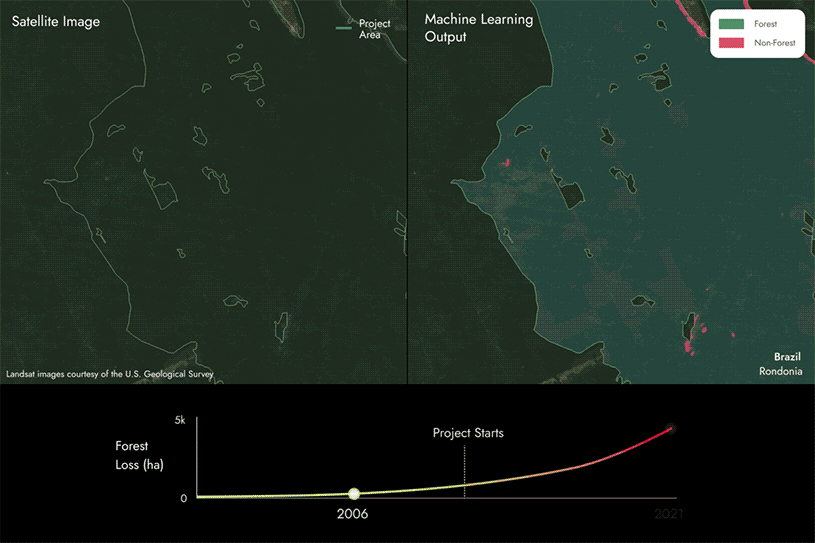
从图中可以看出,部分区域正从森林转变为非森林,这表明随着时间的推移,项目区域内发生了森林减少。
然后,我们将这些结果与项目报告进行对比,以确定它们是否一致,或者是否存在差异。
- 如果我们发现实际森林损失量比报告的更多,那么碳评分将低于100%。未报告的森林损失量越大,评分就越低。
我们如何利用机器学习进行IFM项目分析
“森林管理改善”(IFM)是一类农业、林业和土地利用项目。与常规林业做法相比,这些森林管理活动能够增加森林中的碳储量,和/或减少林业活动产生的温室气体排放。
为了评估IFM项目的成效,我们识别了那些导致碳储量发生变化的已发生活动。我们利用冠层覆盖率作为这些活动的替代指标,并结合深度学习和回归模型,来确定这些活动发生的区域范围。
在下图中,您可以看到一张显示该项目不同区域森林覆盖率相对变化的地图。这些森林覆盖率的变化将对碳储量产生相应的影响。
Sylvera机器学习技术与竞争对手有何不同?
Sylvera机器学习Sylvera专业知识和能力,使我们能够准确获取其他公司无法获取的碳项目信息。此外,我们还投资于未来的研究领域,以确保始终站在行业前沿。
除了传统机器学习(其对每个数据点(即像素)进行独立评估)之外,Sylvera 采用了深度学习算法,这些算法能够更好地理解图像上下文。这使得估算和分析的准确性更高,并能针对不同地区和时间段进行泛化预测。
Sylvera 依赖光学数据,还充分利用了所有可用的地球观测数据:光学数据、合成孔径雷达(SAR)数据以及激光雷达(LiDAR)数据。不久后,我们将把高光谱数据纳入我们的方法体系。
实地验证活动
Sylvera 激光雷达对森林进行扫描,旨在建立全球最大的树木碳储量及地上生物量数据集。
该激光雷达参考数据的数量和质量均属首屈一指。通过在全球不同生物群落中收集海量数据,Sylvera 利用卫星数据,以前所未有的精度估算森林的生物量和碳储量。
.avif)
Sylvera 全球唯一一家利用激光雷达(LiDAR)收集了足够三维森林数据,并将其作为参考数据的评级平台。目前,我们利用这些数据对基于遥感(EO)的机器学习模型进行训练和校准,以提高其准确性。这是我们关键的研究与开发方向之一,未来将应用于我们的评级工作中。




