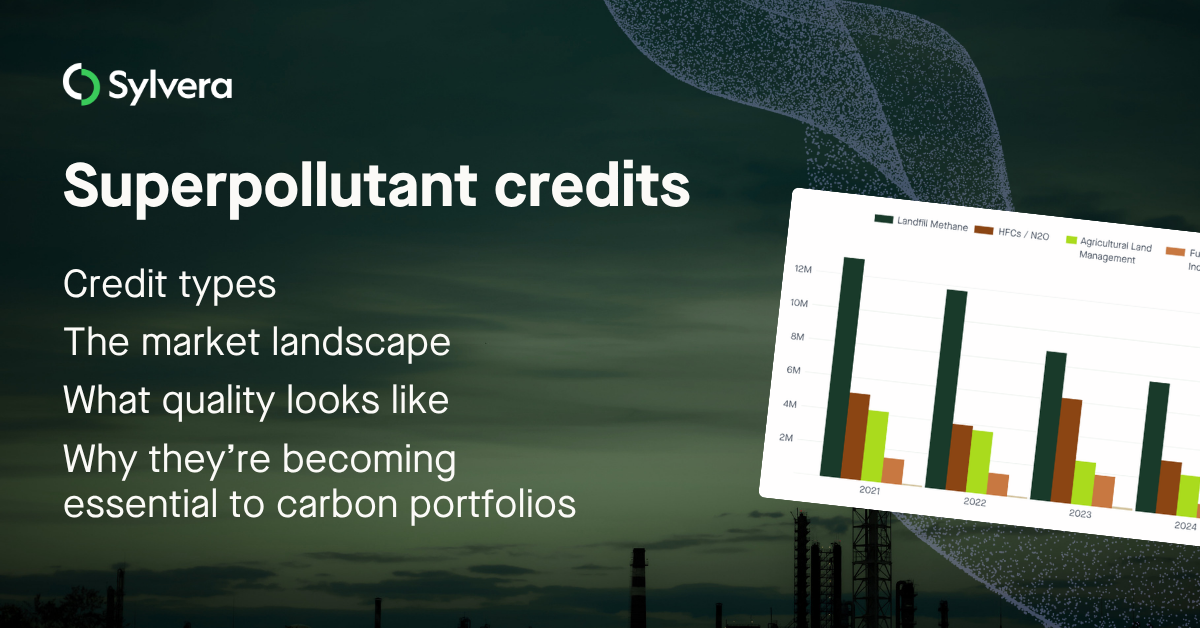
"Ao longo dos anos, investimos significativamente em nossa equipe de dados de campo, com foco na produção de classificações confiáveis. Embora isso garanta a precisão de nossas classificações, não permite a escala dos milhares de projetos que os compradores estão considerando."

Para obter mais informações sobre as tendências de aquisição de créditos de carbono, leia nosso artigo"Key Takeaways for 2025". Compartilhamos cinco dicas baseadas em dados para aprimorar sua estratégia de aquisição.

Mais uma coisa: os clientes do Connect to Supply também têm acesso ao restante das ferramentas da Sylvera. Isso significa que você pode ver facilmente as classificações dos projetos e avaliar os pontos fortes de um projeto individual, adquirir créditos de carbono de qualidade e até mesmo monitorar a atividade do projeto (especialmente se você investiu no estágio de pré-emissão).
Agende uma demonstração gratuita do Sylvera para ver os recursos de compras e relatórios da nossa plataforma em ação.
Ao analisar projetos de carbono, Sylvera utiliza aprendizado de máquina (ML) e vários tipos de dados de satélite para identificar características específicas de florestas e cobertura de terra. Exemplos dessas características incluem:
- floresta vs. não floresta
- altura do dossel
- cobertura do dossel
- biomassa acima do solo
Este artigo descreve como utilizamos o ML para diferentes análises de projetos e como isso nos diferencia da concorrência.
Baixe nossa ficha técnica sobre aprendizado de máquina aqui.
O que é aprendizado de máquina e por que o usamos?
A utilização do ML nos permite ver o que está ocorrendo nas áreas de projeto (PA) em escala. Em vez de amostrar manualmente pequenas áreas em um projeto, o que consome tempo e é menos preciso, podemos avaliar áreas inteiras do projeto, localizadas em qualquer lugar do mundo. Para obter o resultado mais preciso de nossos modelos de ML, treinamos modelos proprietários em biomas e geografias específicos, que são usados para diferentes tipos de projetos de carbono.
Para cada PA, criamos um shapefile (um esboço da área do projeto). Usamos o shapefile para extrair pixels de imagens de satélite que se enquadram no limite do projeto (geralmente resoluções de 10 a 30 m). Sylvera examina cada pixel dentro de um PA, tanto isoladamente quanto no contexto de suas adjacências (que é um recurso poderoso da aprendizagem profunda).
Por exemplo, se estivermos tentando avaliar o crescimento da floresta, usaremos nossos modelos de ML para estimar a altura do dossel de todos os pixels dentro da AP. Para fazer isso, treinamos um modelo para identificar a altura do dossel da floresta, alimentando-o com dezenas de milhares de pontos de dados rotulados. Isso permite que o modelo "aprenda" a identificar os recursos específicos associados à altura do dossel.
Em seguida, executamos nossos modelos em cada área do projeto de carbono para estimar - neste exemplo - a altura do dossel. Ao executar o modelo na mesma área por vários anos, podemos ver as mudanças ao longo do tempo na área florestal.
Combinação de várias fontes de dados
Utilizamos vários tipos de dados para treinar e executar nossos modelos. Cada tipo fornece dados diferentes, o que nos permite detectar recursos específicos.
Como usamos o ML para análise de projetos ARR
Os projetos ARR (Afforestation, Reforestation, Revegetation) são soluções baseadas na natureza que se enquadram na categoria "remoções". Eles geralmente visam converter terras degradadas e estéreis por meio do plantio de árvores.
Para avaliar o desempenho dos projetos de ARR, é essencial identificar as áreas de crescimento de novas florestas, bem como a perda de florestas. Usamos a altura do dossel como um indicador para identificar essas áreas.
As imagens na página seguinte ilustram como utilizamos nossos modelos proprietários de aprendizado de máquina e dados de satélite para identificar áreas de crescimento florestal, estimando a altura do dossel nas áreas do projeto ARR ao longo do tempo.
Neste exemplo, você pode ver o aumento da altura do dossel em diferentes áreas do projeto. Isso indica áreas de plantio e crescimento de novas florestas em diferentes pontos no tempo.
Comparamos esses resultados com os relatórios do projeto para identificar se estão alinhados ou se há discrepâncias.
- Se identificarmos a mesma área de crescimento florestal relatada e nenhuma perda não relatada, então a pontuação de carbono será de 100%
- Se identificarmos uma área de crescimento florestal menor do que a relatada, ou qualquer perda florestal que não tenha sido relatada, a pontuação de carbono será inferior a 100%
A altura do dossel (amarelo e verde) aumenta em diferentes áreas do projeto ao longo do tempo. Isso indica áreas de plantio e crescimento de novas florestas
Como isso informa a classificação de crédito Sylvera ?
Os resultados da nossa abordagem de modelagem são submetidos a um processo de controle de qualidade para garantir que sejam representativos do que realmente está acontecendo no terreno dentro da área do projeto e para assegurar uma alta precisão na pontuação de carbono.
Também usamos nossos resultados de ML no componente de Adicionalidade de nossa estrutura de classificações para testar a inelegibilidade da área do projeto.
- Se, para desenvolver um projeto de compensação de carbono, um desenvolvedor de projeto tiver desmatado qualquer floresta primária que existia antes do início do projeto, a área de floresta desmatada será considerada inelegível e representará um risco de crédito excessivo. Para nos ajudar a entender esse risco, usamos os resultados de nosso ML para rastrear a existência de qualquer floresta primária histórica, além dos momentos em que ocorreu o desmatamento.
Como usamos o ML para análise de projetos de REDD+
Os projetos REDD+ (Redução de Emissões por Desmatamento e Degradação Florestal) são um tipo comum de solução baseada na natureza que se enquadra na categoria "evitar". Eles têm como objetivo preservar as florestas existentes, atribuindo valor financeiro ao carbono armazenado nas florestas e adicionando um incentivo para reduzir o impacto humano que resultaria em emissões de gases de efeito estufa.
Para avaliar o desempenho dos projetos de REDD+, é necessário identificar a perda de floresta em comparação com a floresta mantida durante um período de tempo.
As imagens na página seguinte mostram como utilizamos nossos modelos proprietários de aprendizado de máquina e dados de satélite para identificar áreas de perda florestal, detectando se uma área muda de floresta para não floresta dentro das áreas do projeto REDD+ ao longo do tempo.
Os resultados da nossa abordagem de modelagem são submetidos a um processo de controle de qualidade para garantir que sejam representativos do que realmente está acontecendo no terreno dentro da área do projeto e para assegurar uma alta precisão na pontuação de carbono.
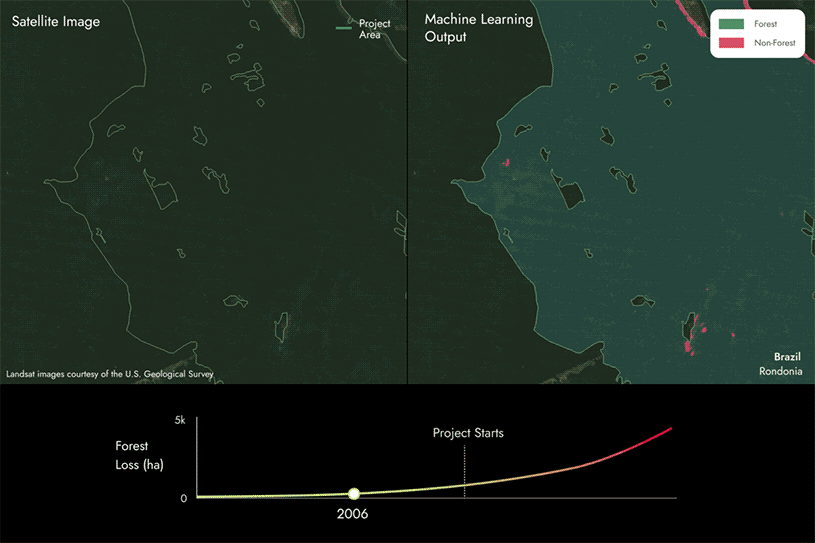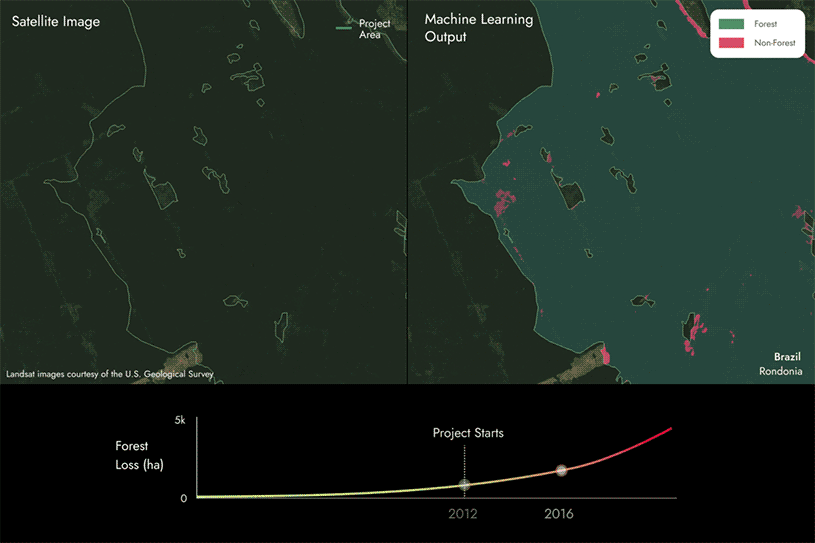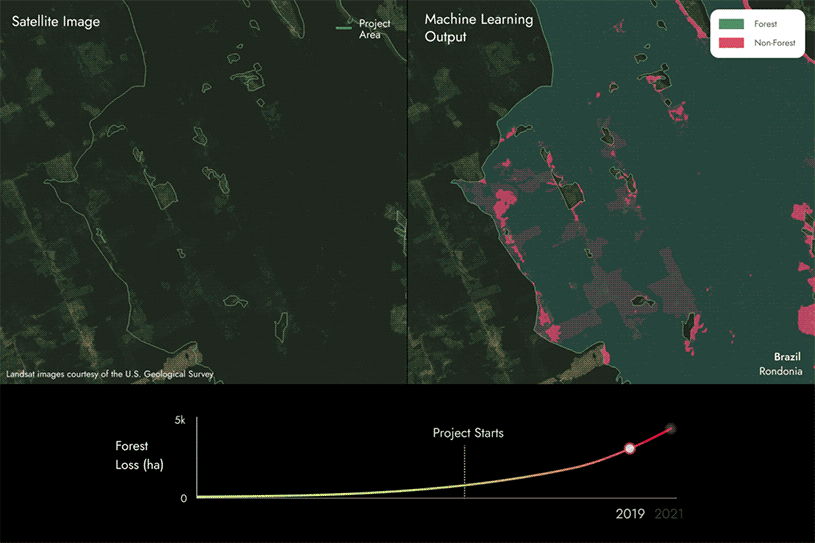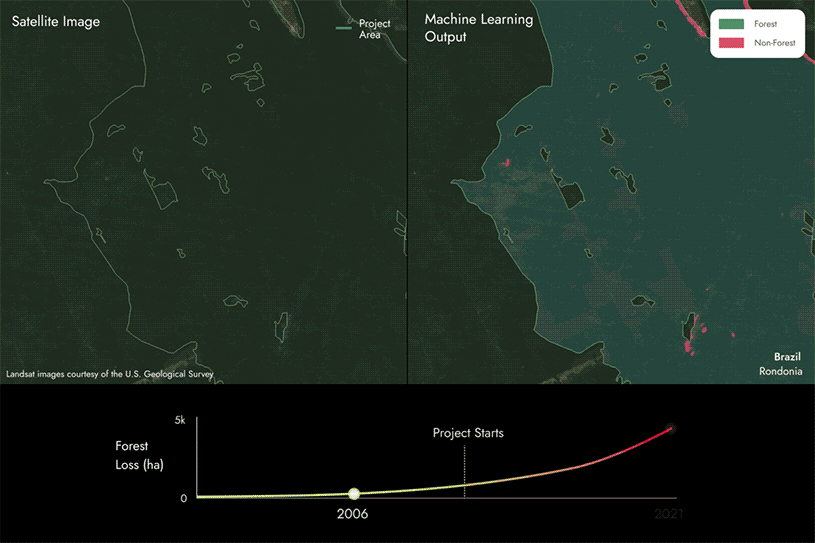
Nesse caso, você pode ver que há algumas áreas que mudam de floresta para não floresta, indicando que houve perda de floresta na área do projeto ao longo do tempo.
Em seguida, comparamos esses resultados com os relatórios do projeto para identificar se estão alinhados ou se há discrepâncias.
- Se descobrirmos que há mais perda florestal do que o relatado, a pontuação de carbono será inferior a 100%. Quanto mais perda florestal não for relatada, menor será a pontuação.
Como usamos o ML para análise de projetos IFM
O Manejo Florestal Aprimorado (IFM) é uma categoria de projeto de agricultura, silvicultura e uso da terra. Essas atividades de manejo florestal resultam no aumento dos estoques de carbono nas florestas e/ou reduzem as emissões de gases de efeito estufa das atividades florestais, quando comparadas às práticas florestais habituais.
Para avaliar o desempenho dos projetos de IFM, identificamos as atividades que ocorreram e que resultaram em uma mudança no estoque de carbono. Usamos a cobertura de dossel como proxy para essas atividades e uma combinação de modelos de regressão e aprendizado profundo para identificar o tamanho da área em que essas atividades ocorreram.
Na imagem abaixo, você pode ver um mapa que indica a mudança relativa na cobertura florestal em diferentes áreas de um projeto. Essas mudanças na cobertura florestal terão um impacto relativo sobre o estoque de carbono.
Como o ML da Sylverase diferencia do de nossos concorrentes?
A experiência e os recursos de aprendizado de máquina da Sylveranos dão a capacidade de obter com precisão informações sobre projetos de carbono que outros não conseguem. Também investimos em futuros fluxos de pesquisa para garantir que estejamos sempre operando na vanguarda do setor.
Além do aprendizado de máquina clássico, que avalia cada ponto de dados (ou seja, pixel) isoladamente, Sylvera também aplica algoritmos de aprendizado profundo, que são capazes de entender melhor o contexto da imagem. Isso permite maior precisão na estimativa e na análise, bem como na previsão generalizada em diferentes regiões geográficas e períodos de tempo.
Sylvera não se baseia apenas em dados ópticos, mas utiliza toda a gama de dados de EO disponíveis: ópticos, SAR/Radar, LiDAR. Em breve, estaremos incorporando dados hiperespectrais em nossa metodologia.
Campanha de esclarecimento de dúvidas
Sylvera está escaneando florestas com LiDAR em um esforço para criar o maior conjunto de dados do mundo sobre carbono armazenado em árvores e biomassa acima do solo.
A quantidade e a qualidade desses dados de referência LiDAR são inigualáveis. Ao coletar grandes quantidades desses dados em todo o mundo em diferentes biomas, isso significa que Sylvera pode estimar a biomassa e os estoques de carbono das florestas com uma precisão sem precedentes usando dados de satélite.
.avif)
Sylvera é a única plataforma de classificação do mundo que coletou dados florestais tridimensionais suficientes usando LiDAR para serem usados como dados de referência. Hoje, usamos esses dados para treinar e calibrar os modelos de aprendizado de máquina baseados em EO para melhorar sua precisão. Esse é um dos nossos principais fluxos de pesquisa e desenvolvimento e será usado em nossas classificações no futuro.